
Why choose Panoptica?
Four reasons you need the industry’s leading cloud-native security solution.

Attack-Path Analysis
Look at paths from diverse angles and get help with risk mitigation and resolution.

Cloud Native Application Security Solution
Reduce tools and vendors as you create secure, compliant cloud native apps.

Code & CI/CD Security
Get real-time vulnerability detection from development to runtime.

Data Security Posture Management (DSPM)
Classify and prioritize your data risks with greater precision aided by enhanced data discovery.

Smart Cloud Detection & Response (Smart CDR)
Real-time attack detection using AI/ML models trained for threat hunting.

Cloud Workload Protection (CWP)
Scale across environments and prioritize real-time risks for cloud workloads.

Cloud Security Posture Management (CSPM)
Scan, monitor, and remediate critical attack paths in your cloud stack instantly.

API Security
Inventory APIs, assess risk, and analyze specs with a single solution.

GenAI Solutions
Dive deeper into cloud risks with industry-leading context-aware GenAI for cloud native application security.
CIEM Solutions
Secure cloud identities by enforcing least-privilege access, reduce identity-based threats, and ensure compliance.

Integrations & Partners
Easily work from one platform with all the tools you already know and love using our integrations.
Get Started
Solutions
Attack-Path Analysis
Look at paths from diverse angles and get help with risk mitigation and resolution.
Cloud Native Application Security Solution
Reduce tools and vendors as you create secure, compliant cloud native apps.
Code & CI/CD Security
Get real-time vulnerability detection from development to runtime.
Data Security Posture Management (DSPM)
Classify and prioritize your data risks with greater precision aided by enhanced data discovery.
Smart Cloud Detection & Response (Smart CDR)
Real-time attack detection using AI/ML models trained for threat hunting.
Cloud Workload Protection (CWP)
Scale across environments and prioritize real-time risks for cloud workloads.
Cloud Security Posture Management (CSPM)
Scan, monitor, and remediate critical attack paths in your cloud stack instantly.
API Security
Inventory APIs, assess risk, and analyze specs with a single solution.
GenAI Solutions
Dive deeper into cloud risks with industry-leading context-aware GenAI for cloud native application security.
CIEM Solutions
Secure cloud identities by enforcing least-privilege access, reduce identity-based threats, and ensure compliance.
Integrations & Partners
Easily work from one platform with all the tools you already know and love using our integrations.


In our latest blog in the Microsoft Defender on AWS Series, we introduced a tool created from the ground up by the Panoptica Office of the CISO, the Amazon Elastic Kubernetes Services (EKS) Creation Engine (ECE). The most obvious question to ask is “why?” Despite the fact there is a large ecosystem of tools for the creation of EKS, we wanted to create ECE to simplify the creation of secure EKS clusters and offer plugins to extend security functionality that did not exist in our idealized vision. This blog is meant to offer up some answers to initial skepticism, go into background about how the tool was created (it was an accident!), use cases for the tool, and an explanation of some of the code pieces.
If you follow the Technical CISO Diaries series (any post by the Panoptica Office of the CISO), or anything specifically from the Panoptica Security Research team, you may know that we pay special attention to Kubernetes. We research it, we use it to host workloads, and have a personal stake in ensuring that it is secure for our customers, our community, and our own use.
If there is one glaring hole in the AWS creation process it is that AWS’ own security best practices are not followed all the time. With EKS, the console experience is that the cluster endpoint is Public, the Nodegroup EBS volumes are unencrypted, logs are off by default, the created security group allows all traffic in a “talk-to-self” rule, Kubernetes Secrets encryption is disabled by default, and you do not get much of a say for Node customization without a bit of a confusing workflow and documentation spread out across three services (EC2, Autoscaling, and EKS). Sure, if you know what you are doing, you can just override those less-than-ideal settings or you can pick up an IaC template, but what about the population that does not know that and explicitly trusts AWS?
As security professionals we often have a bias regarding the distribution of skill, not every single person working in the cloud is a security expert, and not every single security expert specializes in the same areas we do. More to the point, there are companies or individuals running workloads on AWS without formal security oversight or employees at all. Expecting every single person to comb through all documentation and inherently know the race conditions, pitfalls, considerations, and configurations to make every workload secure is preposterous. Using IaC templates require another skillset as well, and the learning curve can be steep to deduce what is being built or if the original author did their due diligence.
This, combined with the fact that we needed a quick way to spin up a bunch of different clusters, bootstrap and test multiple security tools with minimal touch, and test out a variety of operating systems and OS architectures necessitates a quick tool. What was going to be a set of scripts, quickly expanded, as creating the absolute minimum necessary secure configurations across all AWS services to get an EKS Cluster up and running is plentiful. After a bit of polish (with admittedly a lot more to go) ECE was suddenly born and the decision to open source it to benefit the community at large, accelerated development and modularity.
That is the main question though, isn’t it? While we’ll never assume the skill level of all readers of our blog posts, there is a good chance you are (still) balking at this if you even made it this far. As mentioned, it was originally a set of internal scripts that were much more formalized once we realized that there was a need to fill. If you do not want to read our prose (there is some poetry there too), we compiled a quick list for you:
And from our Repository, here is a nice graphic showing the secure defaults you can enjoy by default versus what AWS provides.
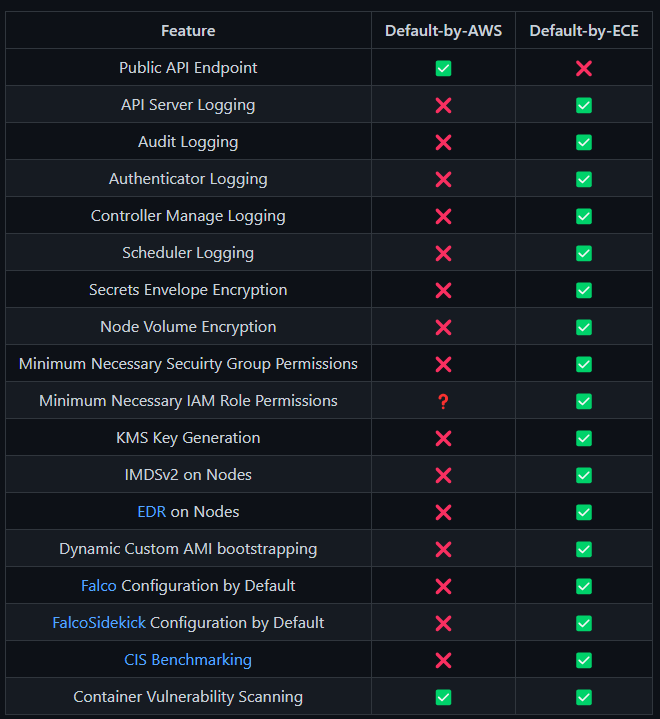
We have already covered the reasons to use this tool over the default AWS console experience, ECE will take care of the creation and configuration of supporting services (EC2 Security Groups, IAM Roles, KMS Keys and Key Policies) to cover the areas that the EKS Console is lacking by default. We go further by ensuring that we can support custom AMIs out of the box, we ensure that all other dependent services are just as secure as your Cluster and apply other AWS best practices which are not followed by default – such as easy configuration of VPC-isolated (private) instances, using Volume Encryption, and using the Instance Metadata Service V2 only.
While it would be easy to create all those different things yourself, via IaC or manually, from experience, bodies of knowledge like that are either isolated or grow out of control. Suddenly, you have a very busy GitHub, Confluence, GitLab, or SharePoint with different CLI commands, scripts (Base64-encoded or not), IaC templates, user guides, AMI IDs sent around Slack channels, and it quickly gets out of control. One of the hardest things to achieve in security is uniform governance – the larger the teams, the more diverse the tech stack, the harder it is to maintain. So, while it is possible to do it on your own, ECE gives you the most secure configurations you can muster by default and generates all those scripts and one-off conditional configurations for you.
Other areas of struggle within the governance storyline are provenance, tracking the age of assets, who created them, what they were created with, and so on. CloudFormation does a good job of applying managed AWS tags but Terraform won’t do it unless you add them per resource, so we did it for you. It is also easy to be lulled into the trap of re-using the same Security Group, same KMS Key, or same IAM Role for every single similar workload you create. This drastically increases the blast radius, not instead of one IAM Role aiding in adversarial (or red team) compromise of your cluster – they can take control of orders of magnitude more. All your infrastructure is still cattle, but it is consolidated into its own fiefdom per run of ECE for a cluster.
Beyond the obvious ease of infrastructure procurement, we also extend ECE into a tool you can use to post-provision your cluster. Installing and configuring tools such as Falco or Datadog are not necessarily hard on their own, but the documentation can be confusing for a first-time user, so we take the guess work out of it. Helm chart management, apply Charts, keeping them updated, ensuring they work with each other? We handle that for you. And while AWS has two native ways to scan containers (Inspector and ECR) we wrapped Trivy and Kube-bench (a CIS benchmark tool) with a unified output in SARIF JSON that you can use on any other EKS cluster.
When it comes to using scripts, one complaint is cleaning up resources, and we also take care of that with ECE. Like a Terraform Apply gone awry or a CloudFormation Stack out of whack, to give you peace of mind we ensure errors of any kind trigger rollbacks to keep orphaned infrastructure questions out of your Slack. This extends to scheduled deletions as well, if you ever wanted to get rid of an EKS Cluster deployed by ECE or otherwise, we will attempt to find all related infrastructure (IAM, KMS, Launch Templates) and remove them safely on your behalf and let you know if we couldn’t. In this way, it gives you the experience of using an IaC tool without the bitter defeat of template errors as you write them on your own.
Note: In this section we will overexplain various arguments, recycle previously provided snippets from the ECE documentation and other blogs, and provide truncated Python snippets. Feel free to skip this section if you are not interested in it.
In our documentation, one of the largest blobs of text is the output of the “help” menu presenting a very large number of arguments, which can be a bit confusing. We have provided different scenario-based inputs you can provide, but it can still use some extra explanation. The centerpiece of the ECE is the “--mode" argument which tells ECE what you want to do. This defaults to creating clusters, but can be used for updates, deletions, or running any over the various module plugins independently and delete them as well. It is a different set of flags completely to apply the different plugins at creation time, as they are all defaulted not to run.
For instance, if you wanted to apply every available installation plugin while you created a cluster while using our default naming conventions for the various resources your command would look like the below snippet, we specify the mode here, but it always defaults to create unless otherwise overridden.
# Ensure you replace the values for empty environment variables below
PRIVATE_SUBNET_ONE='fill_me_in'
PRIVATE_SUBNET_TWO='fill_me_in'
VPC_ID='fill_me_in'
SLACK_WEBHOOK='fill_me_in'
# Ideall you should pull in your API key from a secrets management repo
DATADOG_API_KEY='fill_me_in'
python3 main.py \
--mode Create \
--subnets $PRIVATE_SUBNET_ONE $PRIVATE_SUBNET_TWO \
--vpcid $VPC_ID \
--falco True \
--falco_sidekick_destination_type Slack \
--falco_sidekick_destination $SLACK_WEBHOOK \
--datadog True \
--datadog_api_key $DATADOG_API_KEYTwo notable extras missing from here are installing the Microsoft Defender for Endpoint (MDE) EDR/XDR agent on the Nodes, as well as running the security assessment. As of the time of this writing, we do not support ad-hoc installation of MDE as we include it as part of the Nodegroup bootstrapping within your EC2 Launch Template, ensuring all future added nodes will have the Agent added. We consider a standalone plugin to use AWS Systems Manager Run Command or State Manager to apply the Agents but including them in a Launch Template is the best practice. Security Assessments are easy to run on their own, as we will review later. The following snippet is a modification to the above, this time including MDE installation arguments.
# Ensure you replace the values for empty environment variables below
PRIVATE_SUBNET_ONE='fill_me_in'
PRIVATE_SUBNET_TWO='fill_me_in'
VPC_ID='fill_me_in'
S3_BUCKET='fill_me_in'
SLACK_WEBHOOK='fill_me_in'
# Ideall you should pull in your API key from a secrets management repo
DATADOG_API_KEY='fill_me_in'
python3 main.py \
--mode Create \
--subnets $PRIVATE_SUBNET_ONE $PRIVATE_SUBNET_TWO \
--vpcid $VPC_ID \
--s3_bucket_name $S3_BUCKET \
--mde_on_nodes True \
--falco True \
--falco_sidekick_destination_type Slack \
--falco_sidekick_destination $SLACK_WEBHOOK \
--datadog True \
--datadog_api_key $DATADOG_API_KEYGiven the variety of arguments that we support, we could not use standard Argparse conventions such as using the “Required” flag in any of the argument configurations, given that not every mode will use every possible input. To implement conditional logic, we had to implement it ourselves, using what we called “preflight checks” that are invoked depending on the mode. Just like a normal preflight check that airline Captains, First Officers, and Flight Engineers would go through to plan their flight and takeoffs – we implemented rigorous checklists that will abort if not every condition is met. We did this to avoid orphaned resources being created or lengthy rollback periods being initiated, such as for the destruction and timeout period for Clusters and Nodegroups.
The following is a snippet from the end of our “main.py” file in which we define and parse the input arguments. It shows the various preflight function invocations using a very simplistic “if, elif, else” logic tree. It goes without saying that the snippet is massively truncated as well.
import sys
import re
import boto3
import botocore
import argparse
import subprocess
from art import text2art
import termcolor
from clint.textui import colored, puts
from EksCreationEngine import ClusterManager, UpdateManager, RollbackManager
from plugins.ECEDatadog import DatadogSetup
from plugins.ECEFalco import FalcoSetup
from plugins.ECESecurity import SecurityAssessment
#------
if __name__ == "__main__":
#------
args = parser.parse_args()
mode = args.mode
k8sVersion = args.k8s_version
#------
if mode == 'Create':
create_preflight_check()
elif mode == 'Destroy':
delete_preflight_check()
elif mode == 'Update':
update_preflight_check()
elif mode == 'Assessment':
assessment_preflight_check()
elif mode == 'SetupFalco':
setup_falco_preflight_check()
elif mode == 'RemoveFalco':
setup_falco_preflight_check()
elif mode == 'SetupDatadog':
setup_datadog_preflight_check()
elif mode == 'RemoveDatadog':
setup_datadog_preflight_check()
else:
print(f'Somehow you provided an unexpected arguement, exiting!')
sys.exit(2)The “args = parser.parse_args()” variable is used to load all inputs into memory as their own individual variables, such as what we do with the mode. Since the optional plugins default to false, the only checks we need to perform are to ensure that the associated arguments (which default to a Python “None”) are present, aborting if the script if they’re not there. Outside of that, we must apply conditional checks that the naming conventions do not overlap, and that Subnets and a VPC is supplied for creation as shown in the snippet below.
def create_preflight_check():
#------
eks = boto3.client('eks')
# Conditional check to ensure that AMI ID (if provided) matches regex
amiId = args.ami_id
if amiId != 'SSM':
# AMI Regex
amiRegex = re.compile('^(?:(?:ami)(?:-[a-zA-Z0-9]+)?\b|(?:[0-9]{1,3}\.){3}[0-9]{1,3})(?:\s*,\s*(?:(?:ami)(?:-[a-zA-Z0-9]+)?\b|(?:[0-9]{1,3}\.){3}[0-9]{1,3}))*$')
# Attempt to match
amiRegexCheck = amiRegex.search(amiId)
if not amiRegexCheck:
print(f'Improperly AMI ID provided, does not match regex, check value and submit request again')
sys.exit(2)
# Check if an EKS Cluster exists for provided name
try:
eks.describe_cluster(
name=clusterName
)
except botocore.exceptions.ClientError as error:
# If we have an "ResourceNotFoundException" error it means the cluster doesnt exist - which is what we want
if error.response['Error']['Code'] == 'ResourceNotFoundException':
pass
else:
print(f'An EKS Cluster with the name {clusterName} already exists. Please specify another name and try again')
sys.exit(2)
# Check if an EKS Nodegroup exists for provided name
try:
eks.describe_nodegroup(
clusterName=clusterName,
nodegroupName=nodegroupName
)
except botocore.exceptions.ClientError as error:
# If we have an "ResourceNotFoundException" error it means the cluster/nodegroup doesnt exist - which is what we want
if error.response['Error']['Code'] == 'ResourceNotFoundException':
pass
else:
print(f'An EKS Nodegroup with the name {nodegroupName} already exists. Please specify another name and try again')
sys.exit(2)
# Check for a provided VPC
if vpcId == None:
print(f'VPC ID is required for cluster creation. Please specify a VPC ID and try again.')
sys.exit(2)
# Check for non-empty lists for Subnets
if args.subnets:
pass
else:
print(f'Subnets need to be specified for cluster creation')
sys.exit(2)
# Ensure a S3 Bucket was provided if MDE installation is true
if installMdeOnNodes == 'True':
if bucketName == None:
print(f'S3 Bucket name was not provided. Please provide a valid S3 Bucket and try again')
sys.exit(2)
# Ensure a Datadog API key is provided if Datadog installation is true
if datadogBool == 'True':
if datadogApiKey == None:
print(f'Datadog setup was specified but a Datadog API was not provided. Please provide a valid API key and try again.')
sys.exit(2)
# Call the `builder` function
ClusterManager.builder(
#------
)The drawback of having to implement our own conditional logic is from a development feedback perspective, any additional Plugins that are developed, or arguments that are expanded must be “touched” multiple times. Creation is by far the most rigorous of the various preflight checks, with the others having similar logic applied but much shorter. Another drawback is that we must pass variables through the various Class functions in our core and Plugin libraries which are easy to get lost in. For instance, in the next snippet we show the end of the creation Class (“class ClusterManager()”) where we pickup the arguments that were passed to it from the preflight to determine if we need to run the Plugins, which require importing the Plugins and calling their own Classes separately.
import base64
import sys
import boto3
import botocore.exceptions
import json
from datetime import datetime
import time
import subprocess
import re
from plugins.ECEDatadog import DatadogSetup
from plugins.ECEFalco import FalcoSetup
cache = list()
class ClusterManager():
def builder(kubernetes_version, bucket_name, ebs_volume_size, ami_id, instance_type, cluster_name, cluster_role_name, nodegroup_name, nodegroup_role_name, launch_template_name, vpc_id, subnet_ids, node_count, mde_on_nodes, additional_ports, falco_bool, falco_sidekick_destination_type, falco_sidekick_destination, ami_os, ami_architecture, datadog_api_key, datadog_bool):
# ------
# Setup first time cluster connection with AWS CLI
updateKubeconfigCmd = f'aws eks update-kubeconfig --region {awsRegion} --name {cluster_name}'
updateKubeconfigProc = subprocess.run(updateKubeconfigCmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print(updateKubeconfigProc.stdout.decode('utf-8'))
'''
Send a call into plugins.ECEFalco
'''
if falco_bool == 'True':
FalcoSetup.falco_initialization(
cluster_name=cluster_name,
falco_mode='Create',
falco_sidekick_destination_type=falco_sidekick_destination_type,
falco_sidekick_destination=falco_sidekick_destination,
datadog_api_key=datadog_api_key
)
'''
Send a call into plugins.ECEDatadog
'''
if datadog_bool == 'True':
DatadogSetup.initialization(
cluster_name=cluster_name,
datadog_mode='Create',
datadog_api_key=datadog_api_key
)You can see that “ClusterManager.builder()” takes in many arguments only to use them in certain cases. It is not the most memory efficient, but will likely not be a problem outside of outside help. As of the time of this writing, we are working on improving documentation and our contributors guide. The previous snippets only demonstrate a small portion of the logic and command structure that goes into the backend of ECE. The work is necessary though, as we do it to ensure that all guesswork is taken out of creating a secure EKS Cluster and ancillary services.
As mentioned before, our documentation contains many scenarios and code snippets, and being open-source underneath the Apache-2.0 license means you can view the full code on GitHub, fork it into your own projects or contribute back. We absolutely love working with the community and know that there are much more skilled Python developers out there, so any tweaks for efficiency, readability, and related is just as valuable as expanded functionality. We are planning to support this project for many years ahead and want to make sure it is easy to use and does not cause any issues to end-users.
To wrap up, we wanted to share our plans for ECE, we promise that we won’t continue to try to convince you to use the tool. Our immediate plans are to expand the Plugin ecosystem and provide a developer guide as well as hosting the tool on the Python Package Index (PyPI). The Kubernetes ecosystem is incredibly rich and has everything from Static Analysis Security Testing (SAST), network policy, Policy as Code, ingress controllers, linters, machine learning workloads, cross-platform portability plugins and more available. We would love to include other popular tools such as Tigera’s Calico and AWS’ own extensibility such as AWS AppMesh, ALB Ingress Controllers, and Amazon Elastic MapReduce (EMR) on EKS as a few examples.
Other plans are to continue to improve what we already have based on our own use and community use. We want to continue to push the envelope with security, further reducing the blast radius and using the Panoptica Security Research team’s efforts to inform reduction of AWS IAM permissions and getting away from using AWS-managed policies if possible. We can even go as far as further reducing the Security Group permissibility and expanding that modularity. We also want to expand our list of tools that are supported in our Security Assessment module and offer integration with the Panoptica Platform’s own Kubernetes protection such as agentless Attack Path construction, graph-based analysis, and runtime protection integrations. And finally, bringing our Red Teamer Kubernetes tool, Red-Kube closer into this existing stack and providing our own Falco Custom Rules are all on the horizon.
We look forward to seeing the tool being used more and for any ideas and contributions from the community.
Stay Dangerous.
Try out Panoptica for Free! Create an Account.

